
1- Pourquoi cet algorithme ?
Cet algorithme est souvent nommé aussi KNN (de l'anglais : K Nearest Neighbors).
C'est un algorithme utilisé en machine-learning (algorithme d'apprentissage) et donc fait partie de l'univers des algorithmes dits de l'Intelligence Artificielle.
Le concept de machin-learning est apparu en 1959 par Arthur Samuel, informaticien qui était précurseur dans les jeux sur ordinateur et les programmes d'auto-apprentissages. Il est donc aux origines des concepts d'intelligence artificielle.
L'objectif de l'algorithme KNN est de déterminer, pour une nouvelle donnée, à quelle classe (ou groupe) elle appartient.
L'exemple le plus connu pour expliquer l'algorithme KNN est le classement des fleurs d'iris :

Si on trouve une fleur d'iris dans la nature, l'algorithme des plus proches voisins est capable de vous dire à quelle variété elle appartient parmi toutes les variétés d'iris en utilisant une base de données des fleurs d'iris.
2- Comment fonctionne cet algorithme ?
a- Mise en évidence des classes de données
Afin de mieux comprendre le principe de fonctionnement de cet algorithme, on représente les données sous forme de graphique.
Par exemple, sur le graphique suivant, il est mis en évidence 2 classes de données. C'est-à-dire que la représentation des données permet de mettre en évidence 2 groupes distincts : ceux en vert et ceux en rouge :
 En orange est représenté une nouvelle donnée et on cherche à déterminer à quelle classe elle appartient. Ce seraient nos iris, on chercherait à savoir si cela appartient à telle variété ou telle autre variété d'iris.
En orange est représenté une nouvelle donnée et on cherche à déterminer à quelle classe elle appartient. Ce seraient nos iris, on chercherait à savoir si cela appartient à telle variété ou telle autre variété d'iris.
b- Les k plus proches voisins
À noter l'apparition de K et de cercles (un cercle n'est qu'une représentation d'un calcul qui permet de déterminer les plus proches voisins) :
- dans le plus petit il y a 3 voisins, donc k=3,
- dans le plus grand il y a 7 voisins, donc k=7.
c- Mais comment savoir à quelle classe appartient notre nouvelle donnée ?
On détermine la classe à laquelle notre nouvelle donnée appartient à la majorité.
Par exemple, pour notre graphique ci-dessus :
- pour k=3, cela correspond à la classe verte (il y en a 2 contre 1 en rouge)
- pour k=7, cela correspond à la classe rouge (il y en a 4 contre 3 vertes).
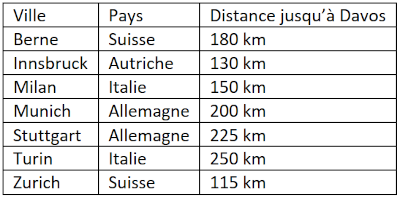
On dispose d’une table de données de villes européennes.
On utilise ensuite l’algorithme des k plus proches voisins pour compléter automatiquement cette base avec de nouvelles villes.
Ci-dessous, on a extrait les 7 villes connues de la base de données les plus proches de Davos.
d- Mais comment choisir K ?
Il faut prendre plusieurs valeurs de K et calculer pour chacune le taux d'erreur de test : on conserve la valeur de K qui minimise ce taux d'erreur.
3- Passons à la pratique
a- Exercice sur Pixees
Vous allez faire entièrement l'activité sur le site Pixees qui utilise l'exemple des fleurs d'iris.
Remarques complémentaires
- À noter que c'est le fichier iris.csv qui sert de base de données de départ avec 150 fleurs différentes et 3 classes (variétés).
La dernière colonne 'species' correspond à la variété d'iris, indiquée par un n° au lieu de son nom latin.
- Éventuellement, pour l'installation des bibliothèques matplotlib, pandas, scikit-learn se reporter à cette page.
- La bibliothèque Pandas est très intéressante pour manipuler facilement des données à analyser, par exemple :
iris=pandas.read_csv("iris.csv") : importe le fichier csv en datafram (se comporte comme un dictionnaire dont les clefs sont les noms des colonnes et les valeurs sont des séries)
x=iris.loc[:,"petal_length"] : crée un tableau d'une seule colonne avec les valeurs de la colonne petal_lenght (explication ici)
b- Amélioration : faire varier k automatiquement
Le point noir du graphique correspondant à un pétale de (longueur=4.5 , largeur=2) montre que l'appartenance à l'espèce versicolor ou virginica est incertain.
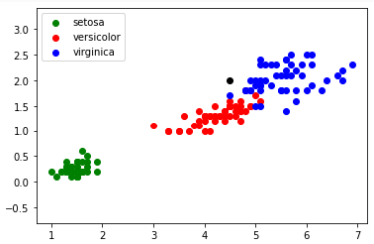
On se propose de faire varier k automatiquement entre 1 et 30 afin de voir comment évolue la prédiction de détermination de l'espèce de ce pétale.
import pandas
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#traitement CSV
iris=pandas.read_csv("iris.csv")
x=iris.loc[:,"petal_length"]
y=iris.loc[:,"petal_width"]
lab=iris.loc[:,"species"]
#fin traitement CSV
#valeurs
longueur=4.5
largeur=2
knn=[]
k=15
#fin valeurs
#graphique
plt.axis('equal')
plt.scatter(x[lab == 0], y[lab == 0], color='g', label='setosa')
plt.scatter(x[lab == 1], y[lab == 1], color='r', label='versicolor')
plt.scatter(x[lab == 2], y[lab == 2], color='b', label='virginica')
plt.scatter(longueur, largeur, color='k')
plt.legend()
#fin graphiqueCompléter le programme python avec une boucle pour faire varier k afin de construire un tableau de couples [k,prediction].
Vous afficherez le tableau pour visualiser la tendance de prédiction suivant les valeurs de k.