
Cette partie reprend des notions abordées en classe de seconde SNT.
Le code ASCII
Le première version du code ASCII (American Standard Code for Information Interchange) a été publié en 1963.
On souhaite coder "L'oie bleue" en code ASCII.
Écrire les codes ASCII (en base 10) de chaque lettre en les séparant du signe moins sans espace.
Le code ISO-8859-1
Le première version de ce code appelé aussi Latin-1 a été publié en 1986.
A noter que ce code permet d'avoir notament le codage des caractères accentués ce qui n'est pas le cas avec le code ASCII.
Le code UNICODE
Plusieurs code sont apparus pour représenter les caractères spécifiques à chaque langue, sans être compatibles entre eux.
En effet, le même nombre décimal représentant un caractère dans une langue ne correspondait pas à celui d'une autre langue.
C'est la raison de la mise en place du codage UNICODE en 1991.
Il existe 3 codages différents : UTF8 - UTF16 - UTF32.
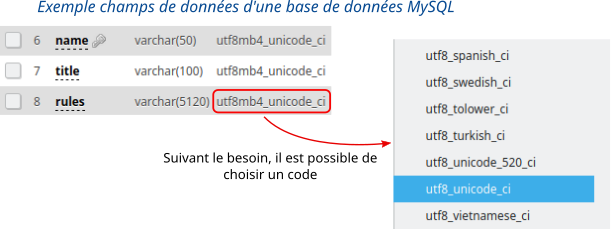
Les bases de données utilisent de nombreux champs de données pour mémoriser l'information.
Lorsque les champs sont créés, il faut définir le type de données, et indiquer pour les champs mémorisant les caractères le code utilisé comme le montre l'exemple ci-dessous :
Tester en python les fonctions chr() et ord().