
Principe du protocole HTTP
Le principe du protocole HTTP s'appuie encore sur le notion de client et serveur losrsqu'un événement survient dans le navigateurLes événements les plus courant sont : un clic sur un lien ou l'url d'un site qui est saisi dans la barre d'adresse.
Pour en découvrir les principes, consulter cette vidéo de l'université de Lille.
Déroulement d'une requête HTTP
Le schéma suivant montre les différentes étape du traitement d'une requête HTTP.
Prenons comme exemple, une page web avec du texte et une image qui est affichée dans le navigateur.
1- L'utilisateur clique sur le lien hypertexte de l'image avec l'intention de l'afficher dans sa taille d'origine :
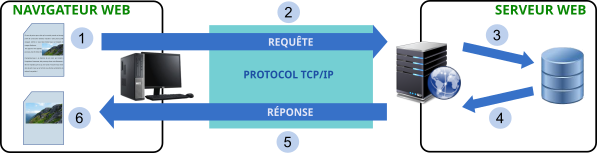
2- La requête est envoyée par le navigateur (exemple chrome) sur internet :
C'est un petit fichier qui contient une en-tête de requête HTTP avec plusieurs paramètres comme le montre l'exemple suivant :

Ce fichier circule sur internet en utilisant le protocole TCP/IP
3- Analyse les en-têtes HTTP, notamment les renseignements permettant de localiser le fichier demandé sur le serveur web.
Vous noterez que la 1ère ligne de l'exemple ci-dessus permet de connaître l'adresse exacte du fichier sur le serveur grâce au chemin.
4- En général, 2 cas de figures existent :
- Si le serveur trouve le fichier demandé (ici une image, mais cela peut être un fichier HTML, une vidéo...), un fichier de réponse est construit avec une en-tête de réponse valide (Généralement Success) et l'image (mais cela peut être le code HTML, une vidéo...)
- Si le serveur ne trouve pas le fichier demandé, un fichier de réponse est construit avec une en-tête de réponse HTTP non valide : la fameuse Erreur 404 !
5- Le fichier réponse est envoyé au navigateur avec plusieurs paramètres et bien sûr la réponse elle-même (une image, un fichier HTML, ...) comme le montre l'exemple suivant :
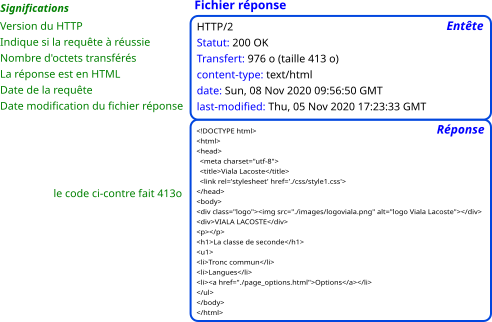
6- Le navigateur analyse la réponse afin d'afficher, dans notre exemple, l'image. Si l'image n'est pas trouvée : un message Erreur 404 sera alors affiché.
Utiliser un navigateur pour observer le protocole HTTP pour afficher une page web
Videz le cache de votre navigateur.
Voici le lien sur une page simple : page_lycee.html
Une fois la page chargée, vous activez l'inspecteur du navigateur ainsi que l'observation du réseau (network).
Vous cliquez alors sur le lien Options afin d'observer les paramètres de la requête et de la réponse correspondant au fichier page_options.html.
Vous voyez qu'il y a beaucoup de paramètres : essayez de retrouver les paramètres dont les significations ont été données précédemment.
a- Quel est le paramètre qui indique la page précédemment chargée ?
b- Quel est l'URL de cette page ?
Le schéma suivant montre comment se charge la page_options.html si le cache du navigateur a été correctement vidé :
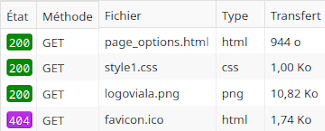
c- Combien de requêtes ont été nécessaire pour permettre l'affichage de page_options.html ?
d- Que signifie un état 200 ?
e- Est-ce que tous les fichiers demandés ont été reçus par le client ?
Le schéma suivant montre comment se charge la page_options.html si la page est chargée plusieurs fois sans avoir vidé le cache du navigateur :
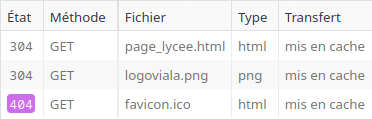
f- Que signifie l'état 304 ?
g- Puisque le fichier est dans le cache de votre navigateur, pourquoi le navigateur a quand même envoyé la requête de demande de fichier ?
h- Quel est l'intérêt de conserver des fichiers dans le cache du navigateur ?